Extracting addresses from millions of pages with AutoML and Ruby
12 February, 2020
I ran into a problem in the past where I needed to extract Australian addresses from a few million pages. Utilising Google’s AutoML NLP (Natural Language Processing) service we can solve the problem of extracting addresses. I’d then need to somehow take those addresses and make them more useful by splitting them into address parts (street no, street name, postcode, state, etc) and geocoding each address(longitude and latitude).
We could then store the data into Elasticsearch and perform geolocation based searches, allowing users to get the distance from their current location to an address listed on a site or filtering sites based on suburbs, states or postcodes.
The diagram below shows how we go from scraping HTML that contains addresses. To address records that are stored in Postgres and Elasticsearch. I’ll mainly focus on the green boxes.

To give you a better idea of what we are expecting, we’ll be going from raw HTML that may contain an address like this:
<html>
<body>
<p>
Contrary to popular belief, Lorem Ipsum is not simply random text. It has roots in a piece of classical Latin literature from 45 BC, making it over 2000 years old.
</p>
<span>address:</span>
<span>Unit 2, Marina Mirage, 74 Seaworld Drive, Main Beach QLD 4217</span>
<span>phone:</span>
<span>11112222</span>
....
</body>
</html>Then transforming each address into something like this:
[1] pry(main)> Address.first
=> #<Address:0x00007fc3ce9a4fb8
id: 1,
site_id: 104,
street_no: nil,
street_name: "Seaworld Drive",
suburb: "Main Beach",
state: "QLD",
postcode: "4217",
lat: -0.27968262e2,
lng: 0.153426398e3,
status: "verified",
nlp_address: "unit 2, marina mirage, 74 seaworld drive, main beach qld 4217",
nlp_confidence: 0.99984866e0,
mappify_confidence: 1,
created_at: Mon, 10 Feb 2020 12:48:35 UTC +00:00,
updated_at: Mon, 10 Feb 2020 14:22:23 UTC +00:00>Scraping sites
You will need to have links to scrape. I won’t provide these but you could buy these online from various places to at least get you started. When scraping you could collect links to other domains that may exist on a page and scrape those as well.
I’ve used Scrapy and deployed it to Scrapy cloud. Scrapy cloud ‘s free plan provides a single process with a one hour run time limit per run. You can run a process as many times as you’d like.
If you need scheduling, Scrapy cloud does not provide it for free. If you want free scheduling you can implement it yourself using their API along with Sidekiq & Sidekiq cron.
Creating training data
This part will be quite tedious but of course, essential. If you were to manually label thousands of addresses, it can take many hours (I know from experience). The prediction model used in the examples of this article has been trained with 2 labels — po_box and address.
Labelling PO box addresses allow us to filter them out when predicting, as they are irrelevant to my requirements. If we don’t teach it the difference, it will return a partial PO box address as an address. This occurs because of the similarity of an address and PO box.
Here are a couple of tools to help annotate your data.
- Label Studio — free
- Doccano — free
- prodigy — paid
At the time I had used Doccano. It didn’t have support to export to Google supported format so I‘ve written my own script to transform the Doccano export file into a format Google AutoML would accept.
I only just found Label Studio, that one looks promising.
There are also services that allow you to outsource this work if it’s within your budget. I can’t advise on this as I just did it myself.
Training a prediction model
We’ll go through the process of taking some training data and creating the prediction model on google cloud.
Setup Google account
- Sign up for an account over at https://console.cloud.google.com (you’ll need to add debit/credit card details to activate the free trial)
- Create a new project e.g
automl-address-extractor
Copy training files to storage
- From the storage section of google, console create a new bucket
- Upload your annotations file to the bucket
- Create a CSV file
google_annotations.csv. The contents should contain the location of the annotations file e.g,gs://bucket-name/google_annotations.jsonl - Upload the CSV file to the bucket the annotations file was uploaded to
Create a google cloud service account
- In cloud console, select “IAM & admin” and choose “Service accounts”.
- Create a new service account
- Select the Role “AutoML Predictor”
- Create key and download the JSON key type
The JSON file contains credentials which you can then use to set environment variables in your project required by the googleauth gem. See .env.example for the env var keys.
Setup AutoML
- Head over to the natural language area of the console under artificial intelligence
- Enable the natural language models API when prompted
- Click on AutoML Entity Extraction
- Click “New Dataset”
- Select the CSV file that was uploaded earlier & import.
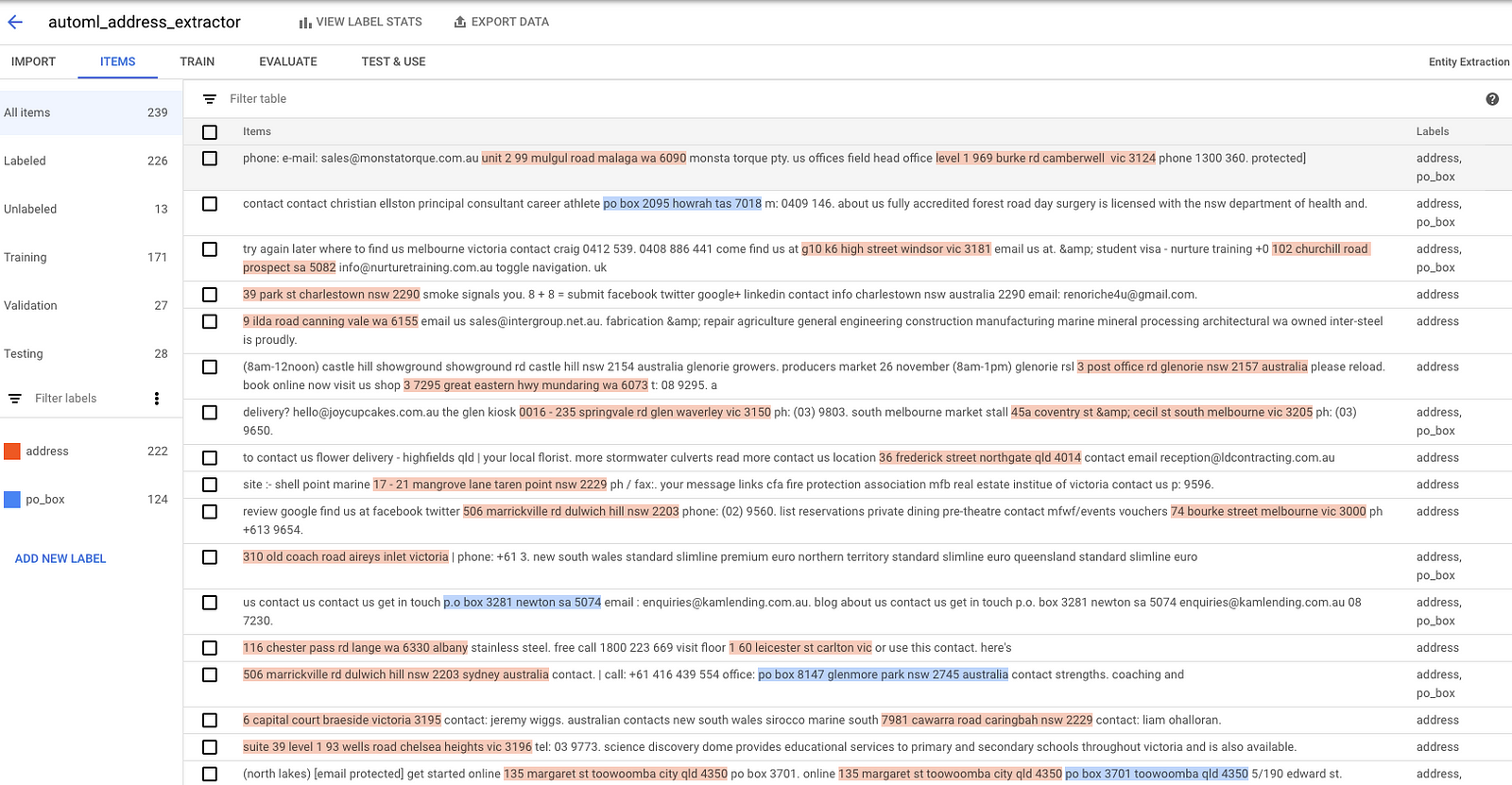
- Your items screen should look something like this
- Go to
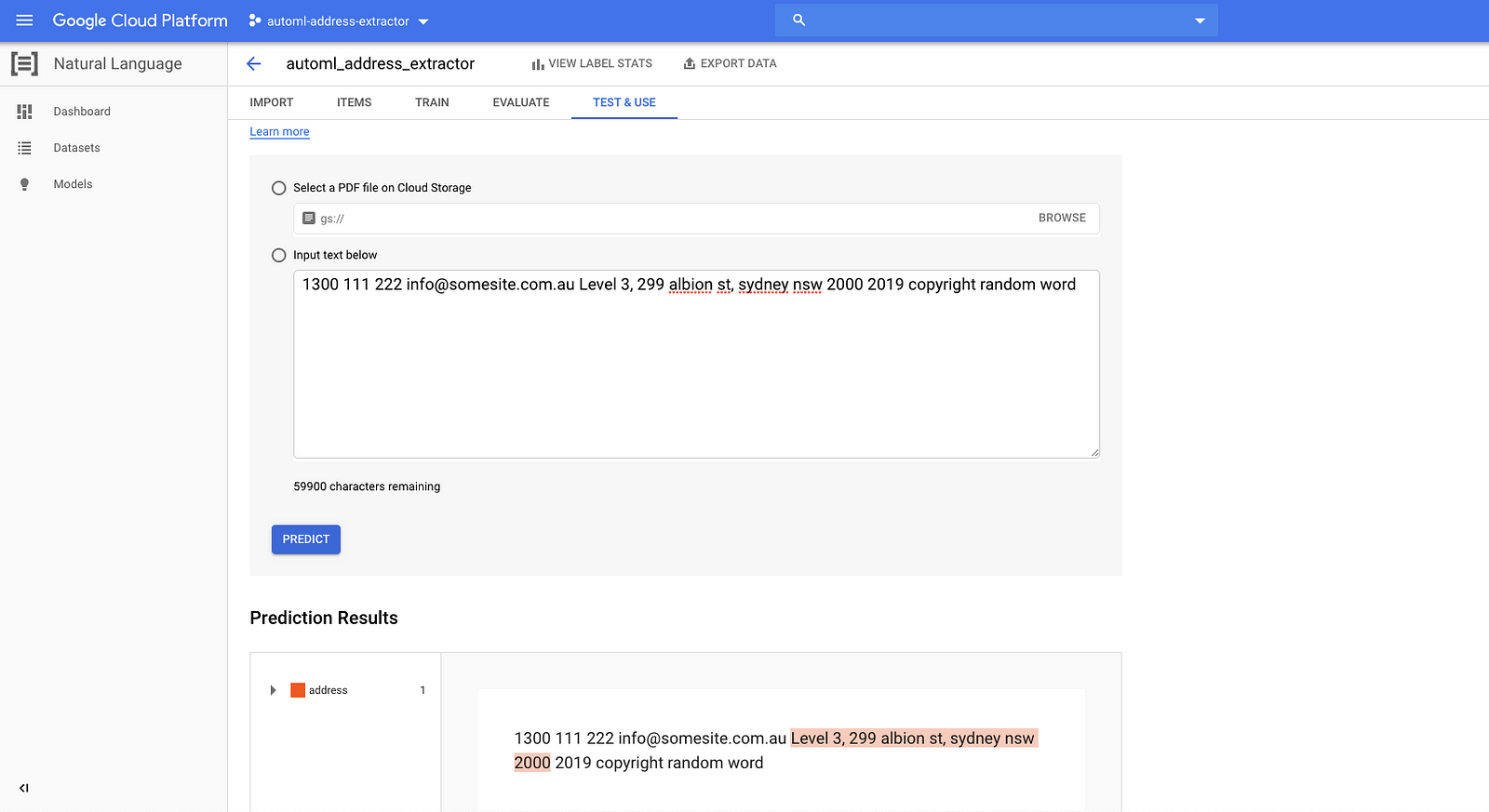
Trainand click the buttonStart Training. This can take several hours. - Once training is finished, you can test out your model in
Test & Use.
Heres an example:
Test prediction API from rails console
Let’s confirm that we can now start predicting addresses with our code within the rails console.
We’ve got an AutoMLClient class that takes a string and returns a prediction from AutoML’s API.
[1] pry(main)> client = AutoMLClient.new
[2] pry(main)> client.predict("1300 111 222 unit 2, marina mirage, 74 seaworld drive, main beach qld 4217 2019 copyright")
=> {"payload"=>
[{"annotationSpecId"=>"7316645151454003200",
"displayName"=>"address",
"textExtraction"=>{"score"=>0.99951684, "textSegment"=>{"startOffset"=>"13", "endOffset"=>"74", "content"=>"unit 2, marina mirage, 74 seaworld drive, main beach qld 4217"}}}]}As you can see AutoML has managed to extract out the correct address from the string.
Cost of predicting
So far so good right? If you’re only running predictions in the thousands that would be okay. But what if we need to process a million or more addresses? The first thing that comes to mind is cost.
Immediately we can reduce costs substantially simply by avoiding sending entire pages to AutoML. Most of the content on a page will be irrelevant and a page can contain hundreds to thousands of characters. Instead, we can extract snippets from a page where we think an address may exist. I’ll explain how we extract snippets later when we go through the code. But just so you know, a snippet may or may not contain an actual address. That’s why we need to use NLP.
Let’s take a look at some approximate numbers and determine if this can be a viable solution. Because of the way snippet extractions work, the number of characters per snippet is variable. But we can take an average of the snippet length and use that when doing the maths. Heres google pricing page if you’re interested.
At the time of writing the costs are:
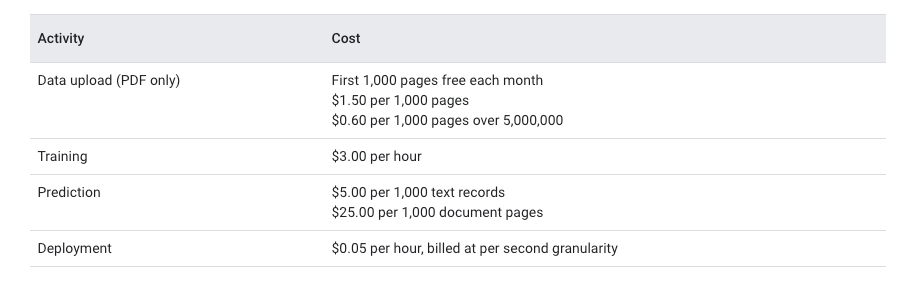
We’re more interested in the prediction pricing of text records — $5 per 1000 text records. If a request is 1000 characters or less, it will work out to be 1 text record. 4500 characters would be 5 text records.
Now let’s take a look out our costs currently for predicting addresses from snippets with AutoML.
One snippet per request
Number of snippets: 1 000 000
The average length of a snippet: 110 characters
$5 per 1000 text records = 5 / 1000 = 0.005
Cost: 1 000 000 * 0.005 = $5000Let’s explore if it’s possible to optimise on cost. By looking at data that has already been collected we know a snippet will have an average length of 110 characters. We also know that google charges per text record of 1000 characters. So what would the costs look like if we could code up a solution to group snippets into blocks of text up to 1000 characters?
Grouping snippets by 1000 characters
1 000 000 * 110 = 110000000 (total number of characters)
Text records: (110000000 / 1000) = 110 000
110 000 * 0.005 = $550We’ll be saving approximately $4450 USD.
Looks much better (if you have free trial credits), but before we move forward, let’s check the limitations of googles API.
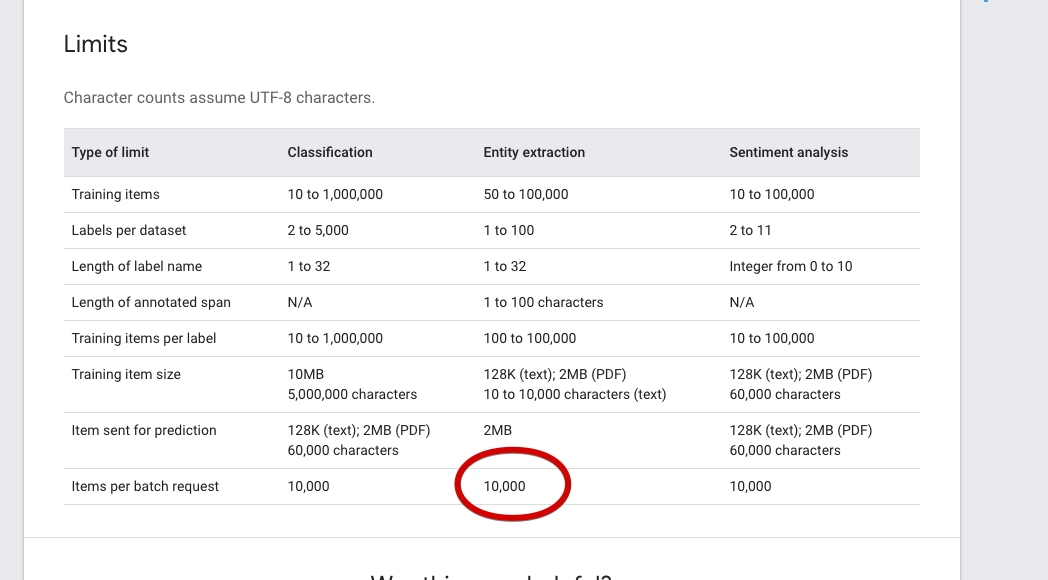
Google allows up to 10000 characters per request. When we group snippets in blocks of 1000 characters, in most cases we won’t get exactly 1000 characters. We could end up with something like 920 or 970. Those missing characters can add up and increase costs over time. So what we’ll do is group snippets in blocks of a maximum of 10000 characters. This will allow us to save a bit more money.
If you’re wondering if AutoML is a good fit for you, it depends on the amount of data you need to process and how much value you can get from that data. If you’re looking to reduce costs further you could implement the entity extraction yourself with spacy. Then build your own prediction API. But that depends on your own personal situation and if the costs of rolling your own solution are worth it.
Google provides a free trial period with $500 credit when setting up a new account. The first 5,000 text records are free during the trial period (5 million characters). That may be enough for you to get a quick MVP out the door, then move on to something like spacy if you need to in the future. There isn’t much stopping you from signing up with another account for more free credits as well. If you’re starting a business, you can also apply for startup credits and get another $3000 credits or more on top.
Extracting addresses with ruby
When we save a page for a site, we store the HTML in our DB. We then strip the HTML and take that result and save it to the content field of a page record. Now we won’t need to worry about HTML when processing.
Extracting snippets
If you look at the snippet extractor code, you’ll see that it will go through each word looking for an Australian state e.g NSW. Once a state has been found, it will extract the surrounding words including the state. This is what we will call the address snippet.
Grouping snippets
Grouping is a bit more complicated. Googles API is expecting a block of text with 10000 characters max. When calling the API, if a prediction is successful it will return the index positions of labels found. We need to take that index position and find the snippet associated with that prediction. The snippet will contain additional information that we require to associate to a site within our DB. So that is the responsibility of the MLContentBuilder class. It will:
- join a collection of snippets, and separate with a full stop.
- keep track of start and end positions of each snippet
- keep track of site id for a snippet
- allow us to look up a snippet at an index position
Snippets are separated with a full stop to improve the accuracy of a prediction.
Entity extraction with AutoML NLP (Natural Language Processing)
There is an ExtractAddress service that we’ll use to go from HTML to extracted addresses. When executed it performs the following:
- Retrieve from the DB pages for multiple sites
- Extract address snippets from pages
- Group snippets to a maximum of 10 000 characters for each group
- Send grouped snippets to AutoML NLP service to extract addresses
- Bulk import into addresses table
Retrieving useful information from an address string
So now we got an address as a string, what now? You may already be familiar with address autocompletion provided by Google or other APIs.
There are several API’s that are Australian address only. I’ve found that those contain more complete data than google. Heres a few Australian addresses only services from a quick search:
Looking at the pricing page, Mappify is the cheapest with 2500 free requests per day. If none of the services is within your budget another option is to build your own address search API using the GNAF dataset. Setting it up is out of the scope of this article, but here are some tips if you’re interested:
- Follow the instructions in this repo to load up the GNAF dataset into Postgres
- If you decide to use rails as your API, you could use Searchkick to sync to Elasticsearch
- Update your model so Searchkick’s callbacks will sync address parts and geolocation data to Elasticsearch
- Create a search endpoint and use Searchkick’s search method to perform searches.
All of the Australian address API’s that I’ve found mention that they are using the GNAF dataset.
We’ll keep things simple and use Mappify as I don’t need to be processing millions of snippets for this article. I’ve modified the extracted code to use Mappify for address lookups.
[1] pry(main)> mc = MappifyClient.new("your-api-key-goes-here")
[2] pry(main)> mc.address_search("unit 2, marina mirage, 74 seaworld drive, main beach qld")
=> {"type"=>"completeAddressRecordArray",
"result"=>
[{"buildingName"=>"MARINA MIRAGE",
"flatNumberPrefix"=>nil,
"flatNumber"=>2,
"flatNumberSuffix"=>nil,
"levelNumber"=>nil,
"numberFirst"=>74,
"numberFirstPrefix"=>nil,
"numberFirstSuffix"=>nil,
"numberLast"=>nil,
"numberLastPrefix"=>nil,
"numberLastSuffix"=>nil,
"streetName"=>"SEAWORLD",
"streetType"=>"DRIVE",
"streetSuffixCode"=>nil,
"suburb"=>"MAIN BEACH",
"state"=>"QLD",
"postCode"=>"4217",
"location"=>{"lat"=>-27.96826181, "lon"=>153.42639831},
"streetAddress"=>"Unit 2, Marina Mirage, 74 Seaworld Drive, Main Beach QLD 4217"}],
"confidence"=>0.9180327868852459}The SearchAddress service will accept addresses that have been extracted with AutoML then look up the address using Mappify’s autocomplete API. It will then bulk update the address records.
Sidekiq Jobs
I won’t cover the code for both services, just the jobs that handle address extraction.
There are two workers involved in the address extraction process.
First is the scheduled job. It will find sites where addresses haven’t been extracted. Then, in batches, it will enqueue another worker, passing it a list of site ids.
The Job that was enqueued will retrieve sites from the ids and execute the ExtractAddress service.
| class Scheduled::ExtractAddressesBatchJob | |
| include Sidekiq::Worker | |
| sidekiq_options lock: :until_and_while_executing | |
| def perform | |
| sites = Site | |
| .select(:id) | |
| .addresses_not_checked | |
| .limit(10_000) | |
| sites.find_in_batches do |batch| | |
| site_ids = batch.pluck(:id) | |
| site_ids.each_slice(500) do |slice| | |
| ExtractAddressesJob.perform_later(slice) | |
| end | |
| timestamp = DateTime.now | |
| Site | |
| .where(id: site_ids) | |
| .update_all(last_address_check_at: timestamp, updated_at: timestamp) | |
| end | |
| end | |
| end |
| class ExtractAddressesJob < ApplicationJob | |
| queue_as :default | |
| def perform(page_ids) | |
| sites = Site.where(id: site_ids).includes(:pages) | |
| ExtractAddresses.process(sites) | |
| end | |
| end |
That’s it, pretty straight forward stuff. I’ve found the most difficult parts are getting the data to train and annotating the data to be used for training.
AutoML can be expensive if you’ve got a lot of data to process. But the free trial can go a long way as well. From the calculations above I can cover the costs of processing a million snippets with the free trial.